
[SORT] Heap Sort (힙 정렬)
Updated:
Goal
- 정렬 알고리즘 중 Heap Sort 에 대해 알기
- Heap Sort의 장· 단점
- 시간 복잡도 이해하기
- 자바로 구현할 줄 알기
Heap Sort (힙 정렬) 알고리즘
-
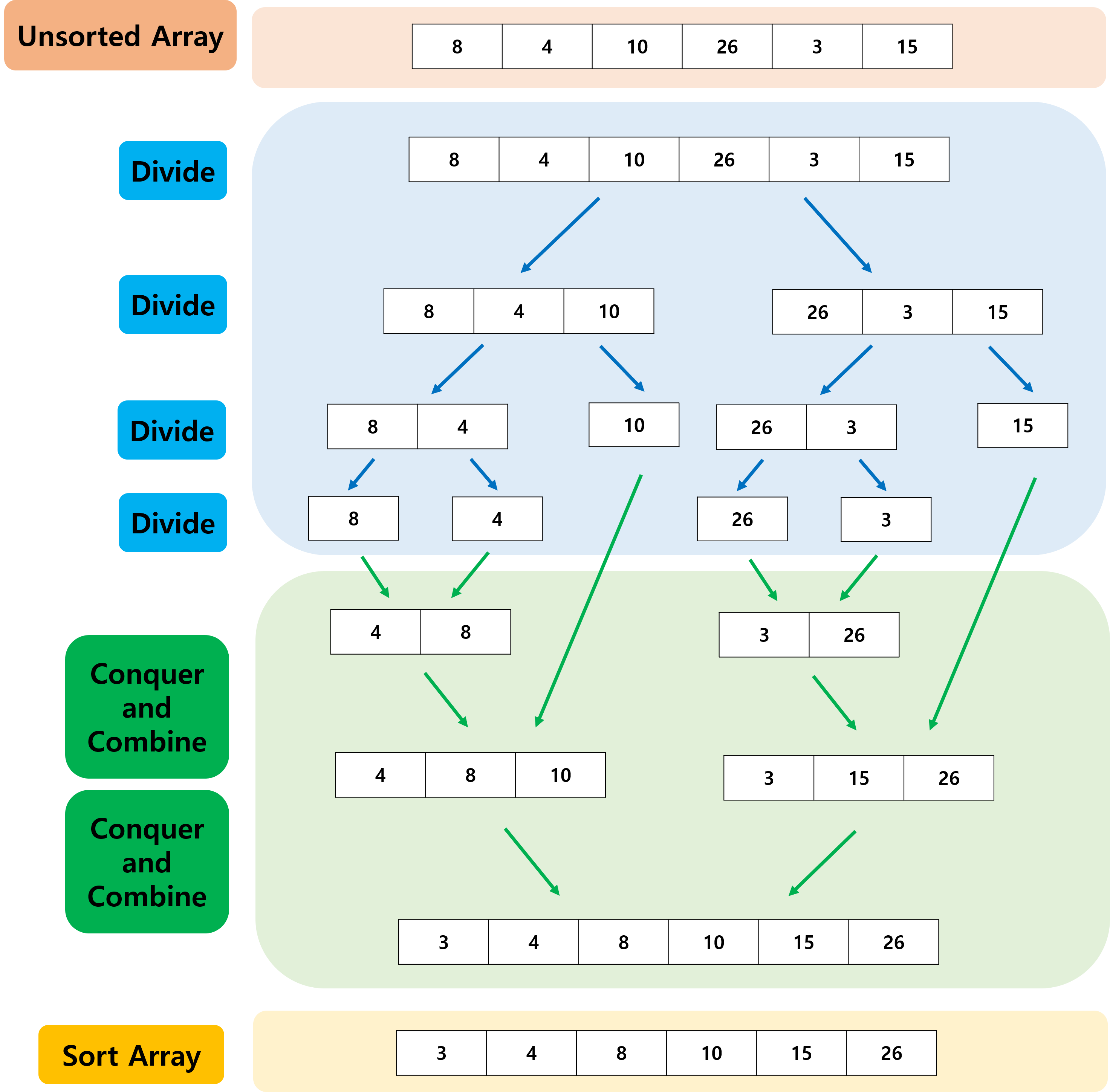
분할 정복(divide and conquer) 방법
- 작은 2개의 문제로 분리하고, 각각을 해결한 후, 결과를 다시 모아 원래의 문제를 해결한다.
-
설명
-
하나의 리스트를 두개의 균등한 크기로 분할한다.
-
더 이상 분할이 불가능 할때까지 (배열의 크기가 1일 때까지) 계속해서 분할한다.
-
분할된 부분 리스트를 순차적으로 정렬한다.
-
정렬된 부분 리스트를 합쳐 전체를 정렬시키는 방법.
-
-
구체적 용어 설명
- 분할(Divide) : 2개의 배열로 분할한다.
- 정복(Conquer) :
- 부분 배열을 정렬한다.
- 순환 호출을 이용해서 분할 정복을 반복한다.
- 결합(Combine) : 정렬된 부분 배열을 합친다.
아래 예시를 통해 이해를 해보자.
Heap Sort (힙 정렬) 의 장 · 단점
- 장점 :
- 안정적이다.
- 데이터가 어떻게 구성되어 있든 간에 시간은 동일하다.
- LinkedList로 구현할 경우, 링크의 index만 변경되므로 임시 배열이 필요하지 않다.
- in-place sort (제자리 정렬) 로 구현이 가능하다.
- 배일의 크기가 큰 경우, LinkedList 사용 시 퀵 정렬보다 더 효율적이다.
- 안정적이다.
- 단점 :
- 임시 배열이 필요하다. (LinkedList로 구현하지 않을 경우)
- in-place sort (제자리 정렬) 이 아니다.
- 배열이 클수록 이동 횟수가 많아 시간이 오래 걸린다.
- 임시 배열이 필요하다. (LinkedList로 구현하지 않을 경우)
Heap Sort (힙 정렬) 의 시간복잡도
배열이 어떻게 정의되어 있든, 무조건 절반씩 부분 리스트로 나눈다. 이러한 점에서 시간 복잡도는 모두 동일하다.
-
분할 단계 (Divide) : 비교 연산과 이동 연산이 수행 X
-
합병 단계 (Conquer and Combine) :
-
비교 연산
- n = 8이라고 가정하자. divide 단계가 끝난 후, [5] [6] 크기가 1인 부분 배열을 합칠 때 2번의 비교 연산이 필요하다. (5< 6인지, 배열이 뒤에 또 존재하는지) , 이를 n=8까지 combine 단계를 진행하면 연산은 각 단계에 n 번이 수행된다.
- depth를 알아보자. n=8일 때, 8은 4로, 4는 2로, 2는 1로 깊이는 3이다. 이를 일반화하면 log₂n 이다.
- 따라서 총 n log₂n
-
이동 횟수
- 임시 배열에 저장했다가, 다시 본 배열에 마지막에 저장하므로 2n의 이동이 발생한다.
- depth 는 log₂n 이므로, log₂n * 2n = 2nlog₂n
-
결과
- T(n) = nlog₂n(비교) + 2nlog₂n(이동) = 3nlog₂n = O(nlog₂n)
-
-
최선의 경우 (Best), 평균 (Avg), 최악의 경우 (Worst)
- O(nlog₂n)
Heap Sort (힙 정렬) JAVA 구현
/**
*
* @FileName MergeSort.java
* @author chlgpdus921
* @date 2020. 4. 4.
*/
public class MergeSort {
static int[] result;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
int n = Integer.valueOf(br.readLine());
int[] arr = new int[n];
result = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int j = 0;
while (st.hasMoreElements()) {
arr[j] = Integer.valueOf(st.nextToken());
j++;
}
mergeSort(arr, 0, n - 1);
for (int i = 0; i < n; i++) {
sb.append(arr[i] + " ");
}
System.out.println(sb);
}
public static void mergeSort(int[] arr, int start, int end) {
//분할하는 function.
// start< end 라는 뜻은 길이가 1보다 크다는 뜻
// start == end일 때 길이가 1이다.
if (start < end) {
mergeSort(arr, start, (start + end) / 2);
mergeSort(arr, (start + end) / 2 + 1, end);
merge(arr, start, (start + end) / 2, end);
}
}
public static void merge(int[] arr, int start, int middle, int end) {
int ls = start;
int rs = middle + 1;
int j = start;
//왼쪽 배열의 start가 middle일때까지
//오른쪽 배열의 start(middle+1)이 배열의 끝일때까지 (end)
while (ls <= middle && rs <= end) {
//왼쪽 오른쪽을 비교하여 result에 순서대로 넣는다.
if (arr[ls] <= arr[rs]) {
result[j++] = arr[ls++];
} else {
result[j++] = arr[rs++];
}
}
//while문이 끝났다는 뜻은 두 배열중 하나의 포인터가 끝났다는 뜻
//남아 있는 배열의 원소들을 result에 넣어준다.
if (ls <= middle) {
for (int i = ls; i <= middle; i++) {
result[j++] = arr[i];
}
}
if (rs <= end) {
for (int i = rs; i <= end; i++) {
result[j++] = arr[i];
}
}
//result값을 기존 배열에 복사
for (int i = start; i < j; i++) {
arr[i] = result[i];
}
}
}
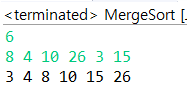
윗 예시를 코드를 통해 똑같이 적용.
n = 6, array = [8, 4, 10, 26, 3, 15]
Leave a comment